Análisis de la precariedad económica juvenil en España (2004-2024)
2/1/26
Introducción
Objetivo
El objetivo de esta investigación no es señalar una única causa, sino desgranar progresivamente los distintos factores que condicionan la realidad económica de los jóvenes. Para ello, se analiza la evolución temporal desde 2004, la posible existencia de brechas de género, el papel que juega el nivel formativo y el impacto de la desigualdad territorial. En conjunto, este análisis busca ofrecer una visión amplia y basada en evidencias técnicas sobre los obstáculos estructurales que impiden la estabilidad financiera de la juventud española, sirviendo a su vez como base para profundizar en la materia en futuros proyectos de investigación.

1.3 TABLA HITOS HISTÓRICOS: 2004, 2014 Y 2024
Código
datos_unificados <- datos_agregados %>%
group_by(Año) %>%
summarise(Porcentaje_Media = mean(Porcentaje_Total), .groups = "drop") %>%
filter(Año %in% c(2004, 2014, 2024)) %>%
mutate(Año_Factor = as.factor(Año))
plot_media <- ggplot(datos_unificados,
aes(x = Año_Factor, y = Porcentaje_Media, fill = Año_Factor)) +
geom_col(width = 0.6, alpha = 0.9) +
geom_text(aes(label = paste0(round(Porcentaje_Media, 1), "%")),
vjust = -0.5, size = 5, family = "serif", fontface = "bold") +
labs(
title = "Evolución de la Precariedad Juvenil en España",
subtitle = "Hitos históricos: 2004, 2014 y 2024 (Media conjunta)",
x = "Año de referencia",
y = "Población con dificultades (%)",
caption = "Elaboración propia a partir de datos del INE"
) +
scale_fill_manual(values = c(
"2004" = "skyblue",
"2014" = "orchid",
"2024" = "gray70"
)) +
theme_minimal() +
theme(
legend.position = "none",
plot.title = element_text(size = 18, face = "bold", hjust = 0.5),
axis.text = element_text(family = "serif", size = 12, colour = "gray17"),
panel.grid.major = element_line(colour = "gray87", linetype = "dashed"),
panel.background = element_rect(fill = "white")
)
plot_media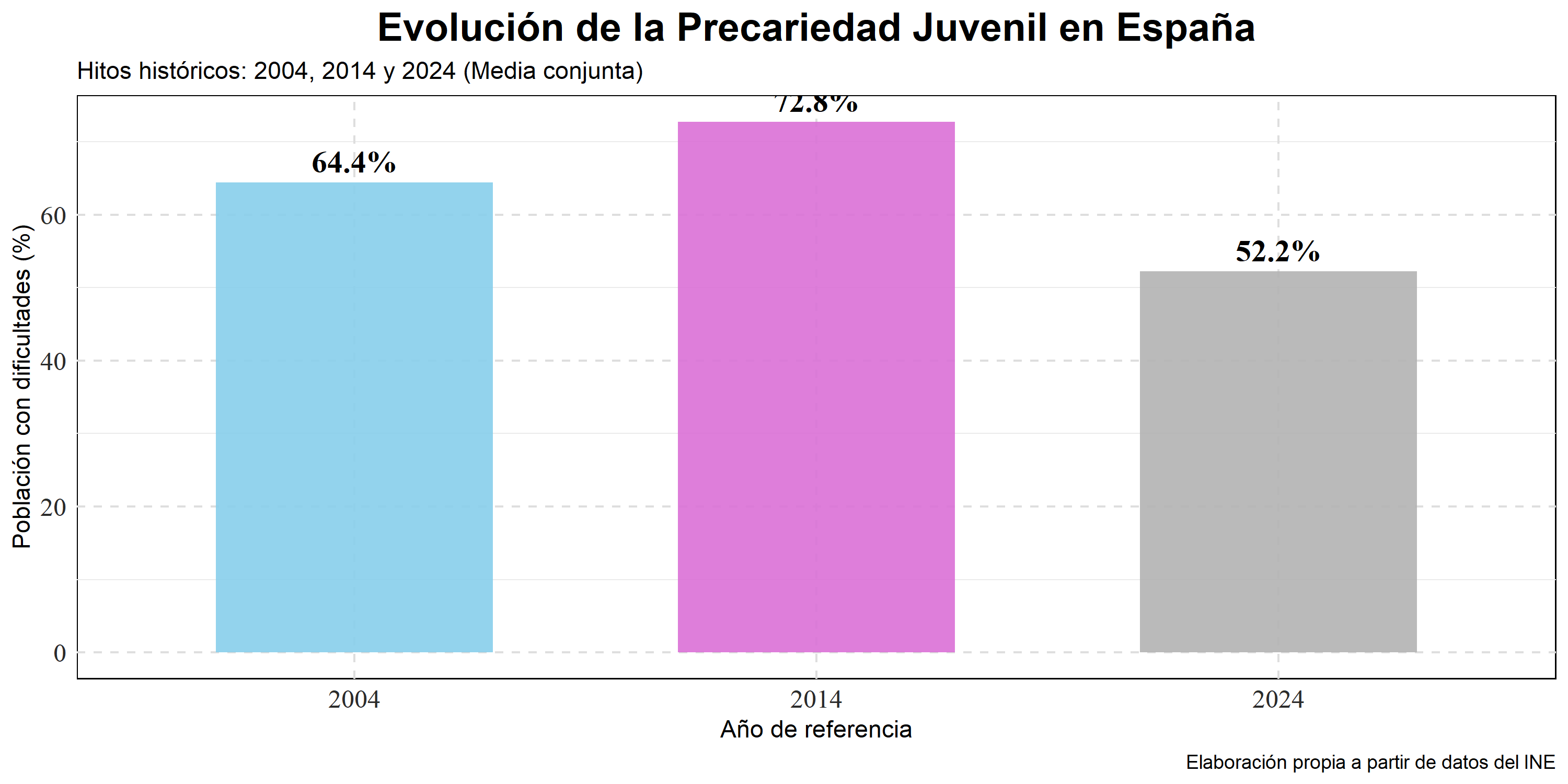
Análisis Tabla 1.3
En este punto, he decidido dejar de lado la distinción por sexos. Como ya he visto en los gráficos anteriores que hombres y mujeres están prácticamente en la misma situación, lo que me interesa ahora es entender cómo ha evolucionado el problema para toda mi generación en tres momentos clave.
Mis conclusiones sobre los datos:
El “misterio” de 2004 y el mileurismo: Me ha sorprendido ver que en 2004 la precariedad era más alta (64.4%) que ahora (52.2%). Mi lectura es que, aunque entonces había mucho empleo, fue cuando nació el concepto de “mileurista”: jóvenes con trabajo pero que con 1.000€ no podían ni plantearse ahorrar por culpa de la burbuja inmobiliaria.
El peor momento (2014): El 72.8% de 2014 es una cifra durísima que refleja el pico real de la crisis. Es el recordatorio de lo mal que lo pasaron los hogares jóvenes tras el estallido de 2008.
2024 y el problema estructural: Aunque el 52.2% es el dato “más bajo”, me parece preocupante. Que hoy en día todavía la mitad de los jóvenes diga que vive al límite demuestra que esto no es una crisis puntual, sino un problema estructural de nuestro sistema económico. Da igual que la economía parezca mejorar; la dificultad para ahorrar se ha quedado estancada en la mitad de la población joven
2.2 GRÁFICO LA BRECHA DE LA FORMACIÓN: COMPARATIVA 2004 VS 2024
Código
datos_brecha_estudios <- datos_estudios_agregados %>%
filter(Año %in% c(2004, 2024)) %>%
pivot_wider(names_from = Año, values_from = Precariedad_Total) %>%
rename(Inicio = `2004`, Actualidad = `2024`)
plot_brecha_estudios <- ggplot(datos_brecha_estudios) +
geom_segment(aes(x = Inicio, xend = Actualidad, y = reorder(Estudios, Actualidad), yend = Estudios),
color = "grey80", linewidth = 2) +
geom_point(aes(x = Inicio, y = Estudios), color = "#A6DBA0", size = 5) +
geom_text(aes(x = Inicio, y = Estudios, label = paste0(round(Inicio, 1), "%")),
vjust = -1.5, size = 3.5, family = "serif", color = "#666666") +
geom_point(aes(x = Actualidad, y = Estudios), color = "#00441B", size = 5) +
geom_text(aes(x = Actualidad, y = Estudios, label = paste0(round(Actualidad, 1), "%")),
vjust = -1.5, size = 4, fontface = "bold", family = "serif", color = "#00441B") +
labs(
title = "Evolución de la Brecha de Precariedad (2004-2024)",
subtitle = "Comparativa del porcentaje con dificultades según nivel de formación",
x = "Porcentaje (%)",
y = "",
caption = "Nota: Punto claro: 2004 | Punto oscuro: 2024"
) +
theme_minimal() +
theme(
text = element_text(family = "serif"),
plot.title = element_text(face = "bold", size = 16),
panel.grid.minor = element_blank(),
axis.text.y = element_text(size = 11, face = "bold"),
plot.margin = margin(10, 10, 10, 10)
)
plot_brecha_estudios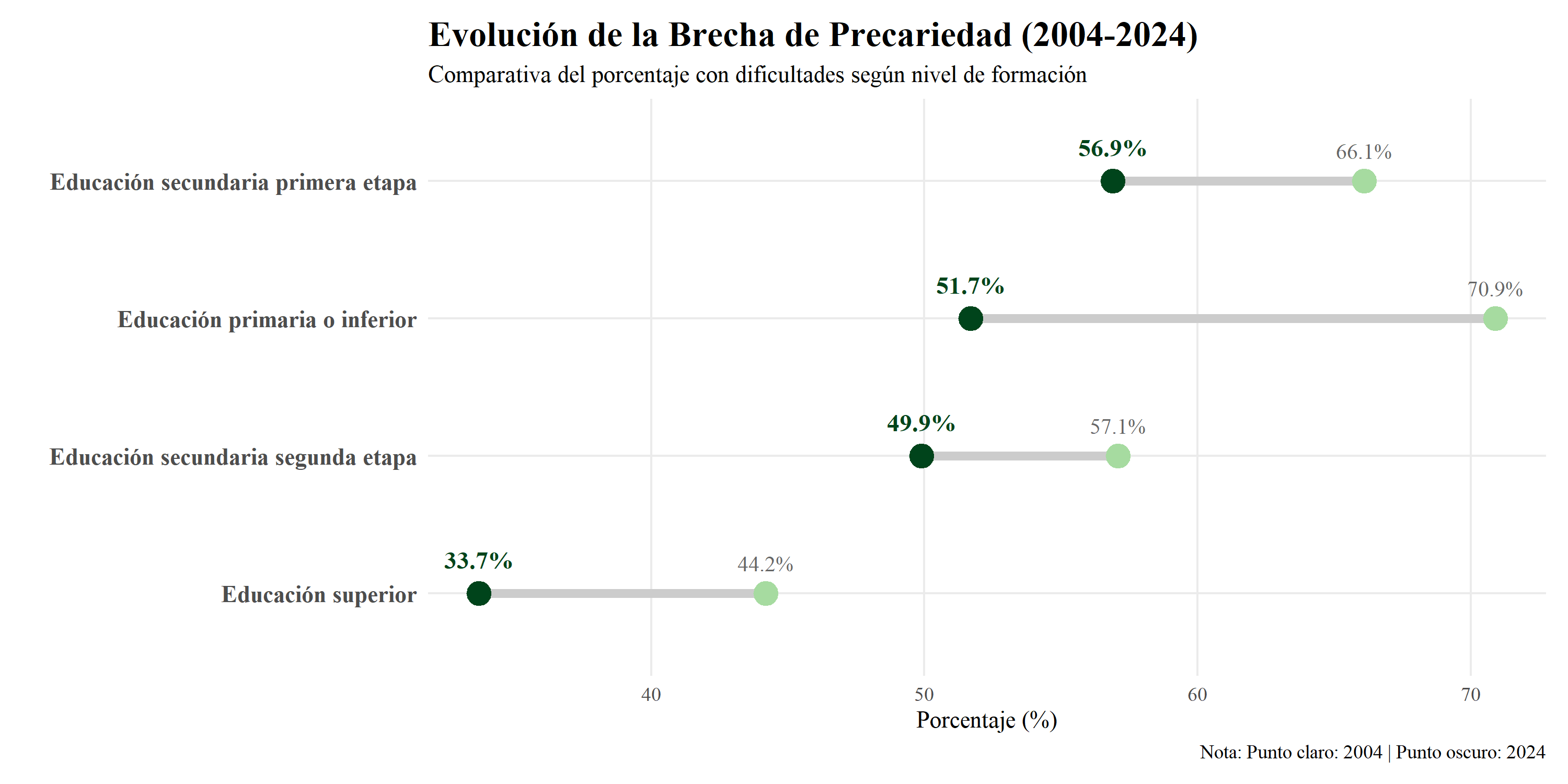
Análisis del Gráfico 2.2
Lo primero que salta a la vista al ver estas “pesas” es que todos los grupos han mejorado. Da igual el nivel de estudios que tengas: todas las bolas oscuras (2024) están a la izquierda de las claras (2004), lo que significa que hoy hay menos gente “ahogada” que hace veinte años.
Pero si miramos los números con detalle, la cosa cambia:
El éxito de la formación superior: Es el grupo que más camino ha recorrido. Ver que los universitarios han bajado del 44,1% al 33,7% nos confirma lo que ya intuíamos en el gráfico de líneas: tener una carrera o una FP superior es lo que más te ayuda a salir de esa zona de peligro.
El estancamiento de la base: Lo que más nos puede preocupar es la parte de arriba del gráfico. Aunque la gente con estudios primarios ha bajado mucho su precariedad (del 71,3% al 51,7%), siguen estando en niveles altísimos. De hecho, los que se quedaron en la primera etapa de secundaria están hoy peor que los universitarios de hace 20 años (56,9% frente a 44,1%).
Si recordamos el primer gráfico, vimos que la precariedad general está estancada en el 52,2%, este gráfico nos da la explicación de por qué pasa eso. No es que todos estemos igual; es que hay una brecha enorme. Mientras un grupo “vuela” hacia la tranquilidad económica, los otros siguen lastrados por debajo de la mitad de la tabla.
3.2 GRÁFICO RELACIÓN ENTRE ABANDONO ESCOLAR Y PRECARIEDAD ECONÓMICA POR CCAA.
Finalmente, para comprobar si existe una correlación entre formación y precariedad a nivel regional, incorporamos un tercer dataset con la Tasa de Abandono Educativo. Al importar estos datos, podemos realizar un join con nuestras variables económicas y verificar estadísticamente si las regiones con menor nivel educativo son también las que presentan mayores índices de vulnerabilidad.
Código
datos_relacion <- precariedad_ccaa %>%
left_join(abandono_2023, by = "ccaa_limpia")
ggplot(datos_relacion, aes(x = tasa, y = porcentaje_precariedad)) +
geom_point(aes(color = porcentaje_precariedad), size = 5) +
geom_smooth(method = "lm", color = "black", linetype = "dashed", se = FALSE) +
geom_text_repel(aes(label = ccaa_limpia), size = 3, max.overlaps = Inf) +
scale_color_viridis_c(option = "magma", direction = -1) +
labs(
title = "RELACIÓN ENTRE ABANDONO ESCOLAR Y PRECARIEDAD ECONÓMICA POR CCAA",
subtitle = "Relación entre formación y dificultad económica por CCAA (2023)",
x = "% Abandono Educativo Temprano (18-24 años)",
y = "% Población con dificultades (Precariedad)",
caption = "Fuente: Elaboración propia a partir del INE"
) +
theme_minimal() +
theme(legend.position = "none", plot.title = element_text(face = "bold")
)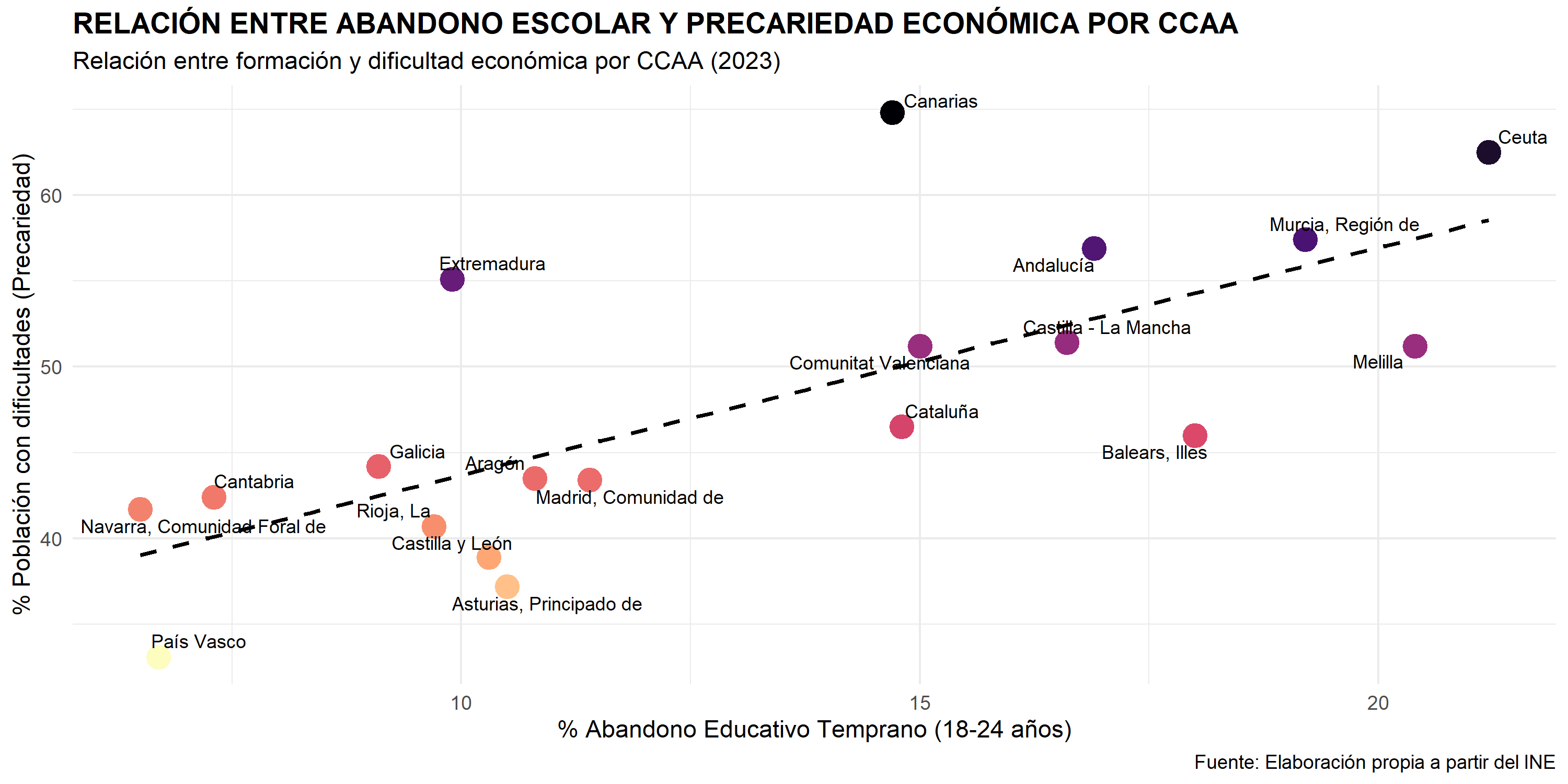
ANÁLISIS GRÁFICO 3.2
Después de ver el mapa y ahora este gráfico de dispersión, creo que la conclusión es bastante clara: la formación es un escudo, pero el territorio es el que marca las reglas del juego.
En el bloque anterior vimos que, a nivel general, estudiar más ayuda a tener mejores ingresos. Aquí, al cruzar el Abandono Escolar con la Precariedad, los datos me dan la razón. Si te fijas en la línea discontinua, se ve una tendencia clara: cuanta más gente deja de estudiar en una comunidad, más familias tienen dificultades para llegar a fin de mes. Es un círculo vicioso: menos estudios, trabajos más precarios y, por tanto, cero capacidad de ahorro.
Como ya adelantaba el mapa del principio del bloque, comunidades como País Vasco o Navarra están en la zona “segura” del gráfico (abajo a la izquierda). Tienen muy poco abandono escolar y eso se traduce en que son las que menos sufren para llegar a fin de mes. En cambio, en el otro extremo (arriba a la derecha), vemos zonas como Andalucía o Murcia, donde el abandono es mucho más alto y la precariedad se dispara.
Lo que más me ha sorprendido es que la línea no es perfecta. Hay comunidades que se salen un poco de la norma. Esto me hace pensar que, aunque estudiar es clave para poder ahorrar, hay “muros” que la formación no puede saltar por sí sola, como el precio de la vivienda en las grandes ciudades o la falta de industria en algunas regiones.